 茶猫云
茶猫云
本文主要介绍python如何批量下载壁纸,非常详细,有一定的参考价值。有兴趣的朋友一定要看!
前言
好久没写文章了,因为最近一直在适应新的岗位,在业余时间学习python。本文是python学习的最新总结。开发了一个爬虫,批量从壁纸网站下载高清壁纸。
注意:本项目仅用于python学习,严禁用于其他用途!
初始化项目
该项目使用virtualenv创建一个虚拟环境,以避免污染整个情况。使用pip3直接下载:
Pip3installvirtualenv然后在合适的地方创建一个新的壁纸-下载器目录,使用virtualenv创建一个名为venv的虚拟环境:
virtualenvvenv。venv/bin/激活下一步,创建一个依赖目录:
最后,yun下载并安装依赖项:
pip 3 install-requirements . txt分析爬虫工作步骤
为了简单起见,我们直接进入分类为“航空”的壁纸列表页面:http://wallpaperswide.com/aer.
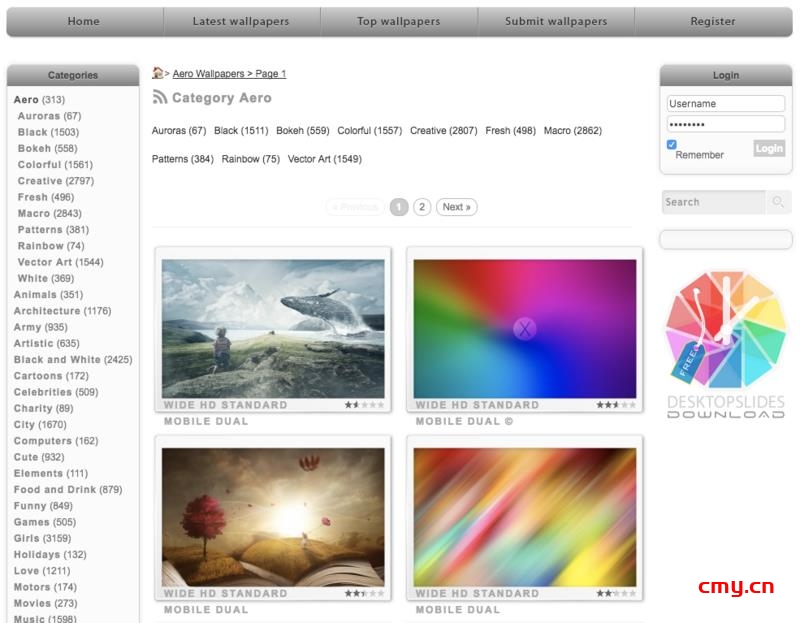
如您所见,本页有10张壁纸可供下载。但是因为这里显示的都是缩略图,作为壁纸的定义远远不够,所以需要进入壁纸详情页才能找到HD的下载链接。点击第一张壁纸,你可以看到一个新的页面:
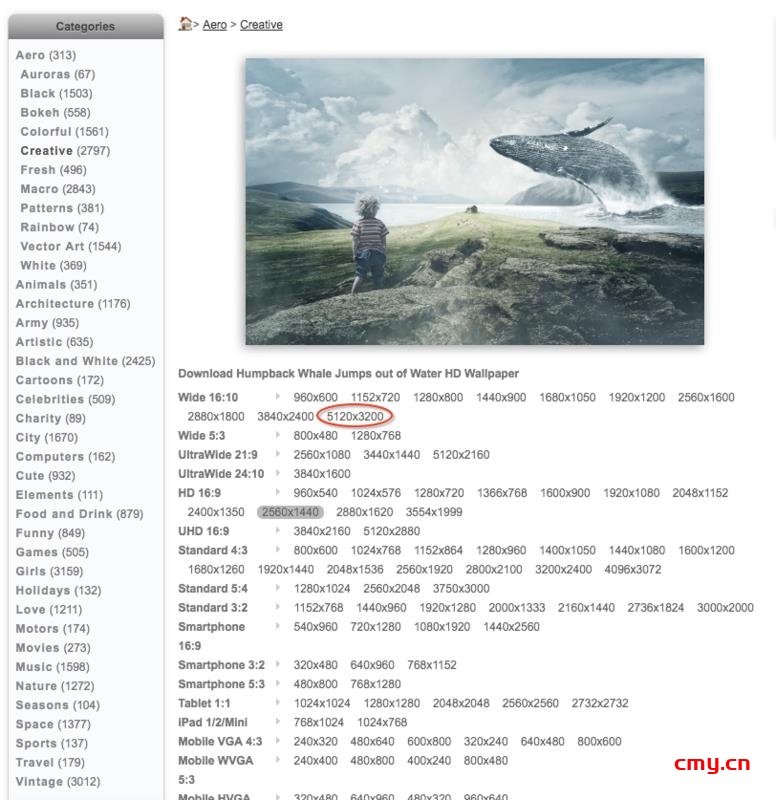
因为我的机器是Retina屏幕,所以打算直接下载最大的,保证高清(红圈显示的音量)。
了解具体步骤后,就是通过开发者工具找到对应的dom节点,提取对应的url。这个过程不再进行,读者可以自行尝试。接下来,输入编码部分。
访问页面
创建一个新的download.py文件,然后引入两个库:
from bs4 import美化组
导入请求接下来,编写一个访问url然后返回页面html的特殊函数:
defvisit_page(url):
标题={
用户代理’ : ‘ Mozilla/5.0(Macintosh;intelmacosx 10 _ 13 _ 1)apple WebKit/537.36(KHTML,like gecko)Chrome/63 . 0 . 3239 . 108 safari/537.36’
}
r=requests.get(url,headers=headers)
r.encoding=’utf-8 ‘
soup=美化组(r.text,’ lxml ‘)
为了防止returnsoup被网站的反抓取机制击中,我们需要通过在头部添加UA来将爬虫伪装成普通浏览器,然后指定utf-8编码,最后以字符串格式返回html。
提取链接
获取页面html后,需要提取该页面壁纸列表对应的url:
defget_paper_link(第:页)
links=page . select(# contentidivullidiva)
collect=[]
forlinkinlinks:
collect.append(link.get(‘href ‘))
函数returncollect将提取列表页面中所有壁纸详细信息的url。
下载壁纸
有了详细页面的地址,我们就可以进去选择合适的尺寸。分析页面的dom结构后,我们可以知道每个大小对应一个链接:

所以第一步是提取对应于这些大小的链接:
墙
paper_source=visit_page(link)
wallpaper_size_links=wallpaper_source.select('#wallpaper-resolutions>a')
size_list=[]
forlinkinwallpaper_size_links:
href=link.get('href')
size_list.append({
'size':eval(link.get_text().replace('x','*')),
'name':href.replace('/download/',''),
'url':href
})
size_list就是这些链接的一个集合。为了方便接下来选出最高清(体积最大)的壁纸,在size中我使用了eval方法,直接把这里的5120x3200给计算出来,作为size的值。
获取了所有的集合之后,就可以使用max()方法选出最高清的一项出来了:
biggest_one=max(size_list,key=lambdaitem:item['size'])
这个biggest_one当中的url就是对应size的下载链接,接下来只需要通过requests库把链接的资源下载下来即可:
result=requests.get(PAGE_DOMAIN+biggest_one['url'])
ifresult.status_code==200:
open('wallpapers/'+biggest_one['name'],'wb').write(result.content)
注意,首先你需要在根目录下创建一个wallpapers目录,否则运行时会报错。
整理一下,完整的download_wallpaper函数长这样:
defdownload_wallpaper(link):
wallpaper_source=visit_page(PAGE_DOMAIN+link)
wallpaper_size_links=wallpaper_source.select('#wallpaper-resolutions>a')
size_list=[]
forlinkinwallpaper_size_links:
href=link.get('href')
size_list.append({
'size':eval(link.get_text().replace('x','*')),
'name':href.replace('/download/',''),
'url':href
})
biggest_one=max(size_list,key=lambdaitem:item['size'])
print('Downloadingthe'+str(index+1)+'/'+str(total)+'wallpaper:'+biggest_one['name'])
result=requests.get(PAGE_DOMAIN+biggest_one['url'])
ifresult.status_code==200:
open('wallpapers/'+biggest_one['name'],'wb').write(result.content)
批量运行
上述的步骤仅仅能够下载第一个壁纸列表页的第一张壁纸。如果我们想下载多个列表页的全部壁纸,我们就需要循环调用这些方法。首先我们定义几个常量:
importsys
iflen(sys.argv)!=4:
print('3argumentswererequiredbutonlyfind'+str(len(sys.argv)-1)+'!')
exit()
category=sys.argv[1]
try:
page_start=[int(sys.argv[2])]
page_end=int(sys.argv[3])
except:
print('Thesecondandthirdargumentsmustbeanumberbutnotastring!')
exit()
这里通过获取命令行参数,指定了三个常量category, page_start和page_end,分别对应着壁纸分类,起始页页码,终止页页码。
为了方便起见,再定义两个url相关的常量:
PAGE_DOMAIN='http://wallpaperswide.com' PAGE_URL='http://wallpaperswide.com/'+category+'-desktop-wallpapers/page/'
接下来就可以愉快地进行批量操作了,在此之前我们来定义一个start()启动函数:
defstart():
ifpage_start[0]<=page_end:
print('Preparingtodownloadthe'+str(page_start[0])+'pageofallthe"'+category+'"wallpapers...')
PAGE_SOURCE=visit_page(PAGE_URL+str(page_start[0]))
WALLPAPER_LINKS=get_paper_link(PAGE_SOURCE)
page_start[0]=page_start[0]+1
forindex,linkinenumerate(WALLPAPER_LINKS):
download_wallpaper(link,index,len(WALLPAPER_LINKS),start)
然后把之前的download_wallpaper函数再改写一下:
defdownload_wallpaper(link,index,total,callback):
wallpaper_source=visit_page(PAGE_DOMAIN+link)
wallpaper_size_links=wallpaper_source.select('#wallpaper-resolutions>a')
size_list=[]
forlinkinwallpaper_size_links:
href=link.get('href')
size_list.append({
'size':eval(link.get_text().replace('x','*')),
'name':href.replace('/download/',''),
'url':href
})
biggest_one=max(size_list,key=lambdaitem:item['size'])
print('Downloadingthe'+str(index+1)+'/'+str(total)+'wallpaper:'+biggest_one['name'])
result=requests.get(PAGE_DOMAIN+biggest_one['url'])
ifresult.status_code==200:
open('wallpapers/'+biggest_one['name'],'wb').write(result.content)
ifindex+1==total:
print('Downloadcompleted!\n\n')
callback()
最后指定一下启动规则:
if__name__=='__main__': start()
运行项目
在命令行输入如下代码开始测试:
python3download.pyaero12
然后可以看到下列输出:
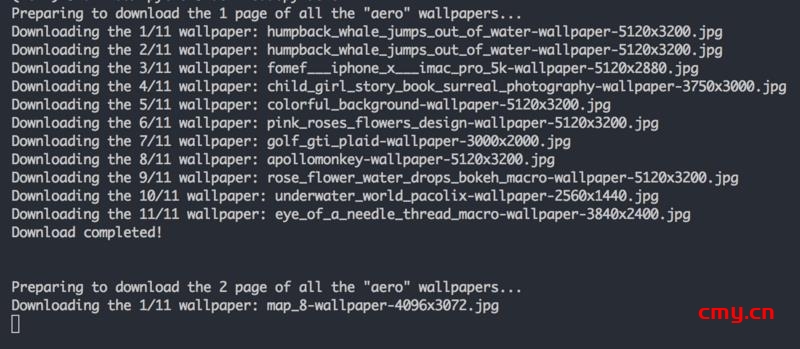
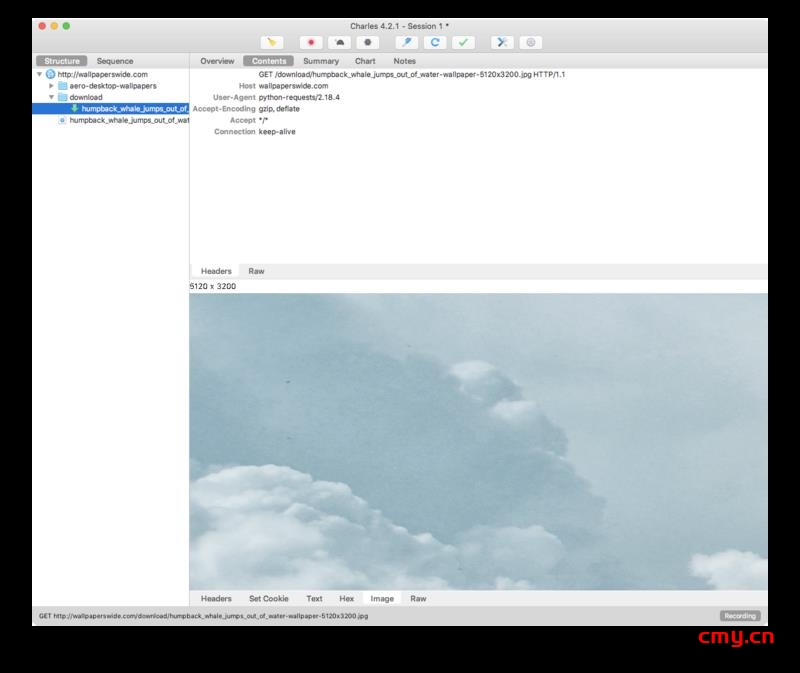
拿charles抓一下包,可以看到正在脚本正在平稳地运行中:
此时,下载脚本已经开发完毕,终于不用担心壁纸荒啦!
以上是“python如何实现壁纸批量下载”这篇文章的所有内容,感谢各位的阅读!希望分享的内容对大家有帮助,更多相关知识,欢迎关注亿速云行业资讯频道!
【本文内容来源于IDC同行网站,若侵权,请联系我们删除】

